
A large language model (LLM) is a critical components of natural language processing (NLP), a subset of artificial intelligence (AI), that has been trained on a massive dataset of text and code. This allows these models to generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. This is what we refer to as generative AI.
Open Source LLMs
In recent years, there has been a growing number of open-source LLM models available. While not an exhaustive list, below are a number of LLM models that we have evaluated at Genzeon:
- GPT-3 (Generative Pre-trained Transformer 3)
- BERT (Bidirectional Encoder Representations from Transformers)
- XLNet
- T5 (Text-to-Text Transfer Transformer)
- ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
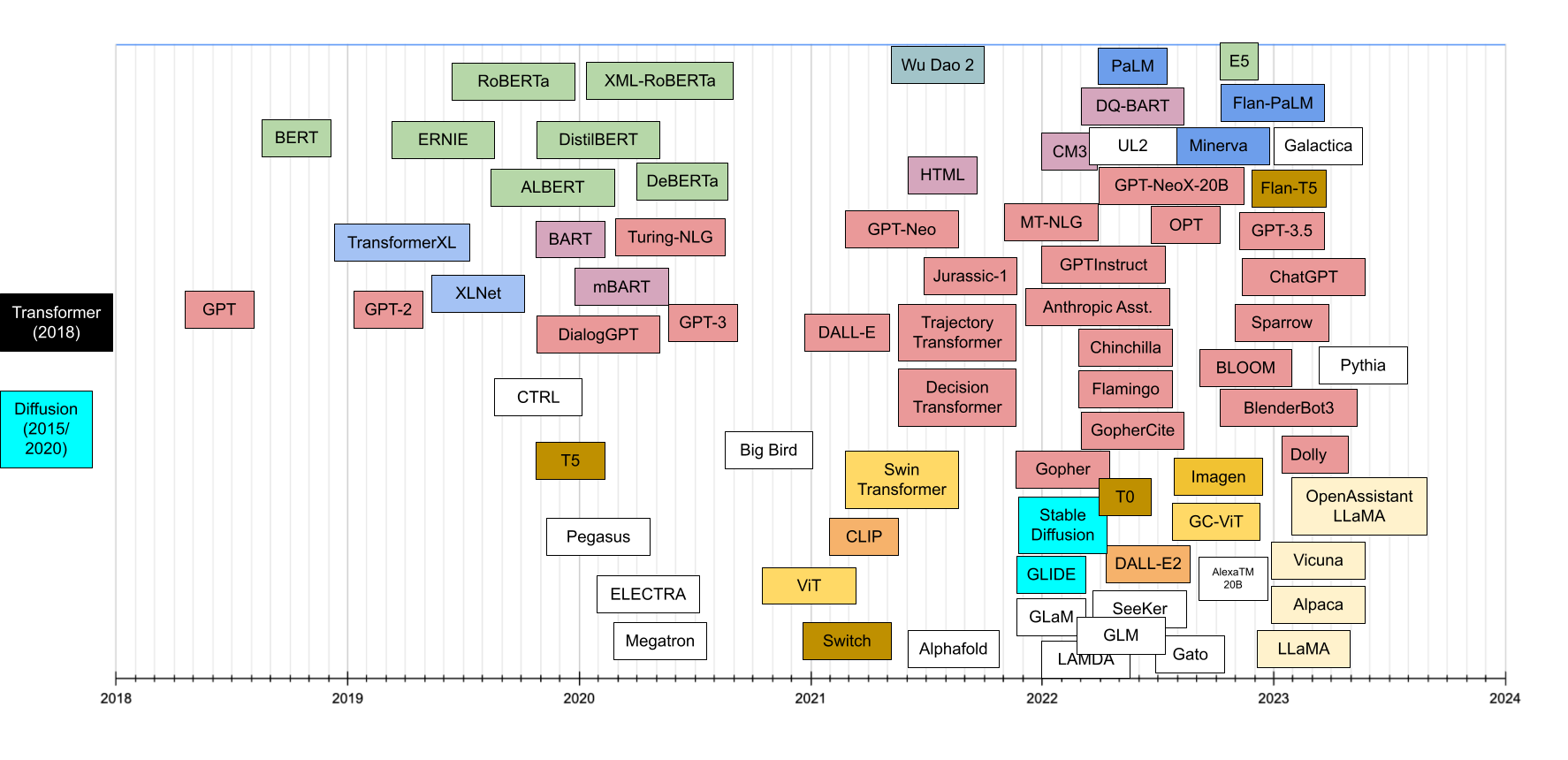
Fig. 1: Chronological view of LLM model transformers. Source: Xavier Amatriain.
Factors for Evaluating Open Source LLMs
The growth in LLM model creation is great news for developers, as it gives them more options to choose from. However, it can also be difficult to know which model is right for you.
That's why it's important to evaluate open-source LLM models before you use them. There are a few different factors you should consider when evaluating an LLM model, including:
- Performance: How well does the model perform on a variety of tasks?
- Fluency: How natural and readable is the text that the model generates?
- Coherence: How well does the model maintain a consistent train of thought?
- Accuracy: How accurate is the model in answering questions?
- Bias: Does the model exhibit any biases?
- Safety: Is the model safe to use?
Ways to Evaluate Open Source LLMs
There are several different ways to evaluate LLM models, including using a benchmark suite and using your own data.
Benchmark suites are a set of tasks that are designed to measure the performance of LLM models. Some popular benchmark suites include:
- Evals: Evals is a framework for evaluating LLMs and LLM systems. It includes an open-source registry of challenging evals.
- Open LLM Leaderboard: The Open LLM Leaderboard tracks, ranks, and evaluates LLMs and chatbots as they are released.
- Chatbot Arena: Chatbot Arena is a benchmark platform for large language models (LLMs) that features anonymous, randomized battles in a crowdsourced manner.
Another way to evaluate LLM models is to use your own data. If you have a specific task that you want to use an LLM model for, you can train the model on your own data. This will allow you to measure the performance of the model on your specific task.
Once you have evaluated an LLM model, you will be able to decide whether it is the right model for you. If you are still unsure, you can consult with a developer who is familiar with LLM models.
Conclusion
Evaluating open-source LLM models can be a seemingly daunting task, but it is important to do your research before you use a model. By considering the factors listed above, you can be sure to choose an LLM model that is right for your needs.



